The Future that Never Happened
Come on a journey with us. Explore the difficulties and opportunities in unravelling cause and effect, within the scope of an on-demand transit system! Jerome Mayaud Jerome Mayaud Lead Data Scientist at Spare More posts by Jerome Mayaud.


Changing the way a transit service is run is never easy: there are many moving parts, and unintended consequences can sometimes be severe. The Spare Engine simplifies the process of pulling the levers of a city’s transportation system, but how can we be sure that the changes we make benefit our customers? Data science, to the rescue!
In this blog post, we’ll:
- Explore the difficulties in unravelling cause and effect, and specifically why correlation does not imply causation;
- Introduce the concept of causal inference, a neat approach that helps us attribute an effect to a cause;
- Show how we applied causal inference to analyze the impact of an efficiency experiment we conducted on a Spare-powered transit service.
Unravelling cause and effect
A question we data scientists often get from our colleagues is: ‘what effect did x have on y?’ At Spare, the ‘x’ could involve adding more buses to a service or altering our routing algorithm, while the ‘y’ could be a change in cancellation rates, rider reviews or the profitability of a service.
We rely on a variety of tools to answer such questions, many of which fall under the category of statistical inference. If you’ve heard of hypothesis testing, confidence intervals or p-values, the chances are it was all about statistical inference. It seeks to describe the relationship between two or more variables, assuming you have a sample that is smaller than the entire population of those variables. You should feasibly be able to collect more data than you currently have, and in doing so, get closer to the ‘true’ relationship between the variables.
One of the most common methods used in statistical inference is correlation. In essence, correlation tells us how strongly a pair of variables are related and change together. Crucially though, it tells us nothing about how and why the relationship exists, just that it exists. For example, there is usually a strong correlation between the number of ice-creams sold and the number of sunglasses sold on any particular day. Typically, as sales of ice-creams rise, so do sales of sunglasses.
Of course, this doesn’t mean the sale of an ice-cream causes the sale of a pair of sunglasses (or vice versa). Instead, the two variables are linked by what we call a lurking (or hidden) variable – in this case, sunshine. When it is sunnier, people tend to buy more ice cream, and also to buy more sunglasses.
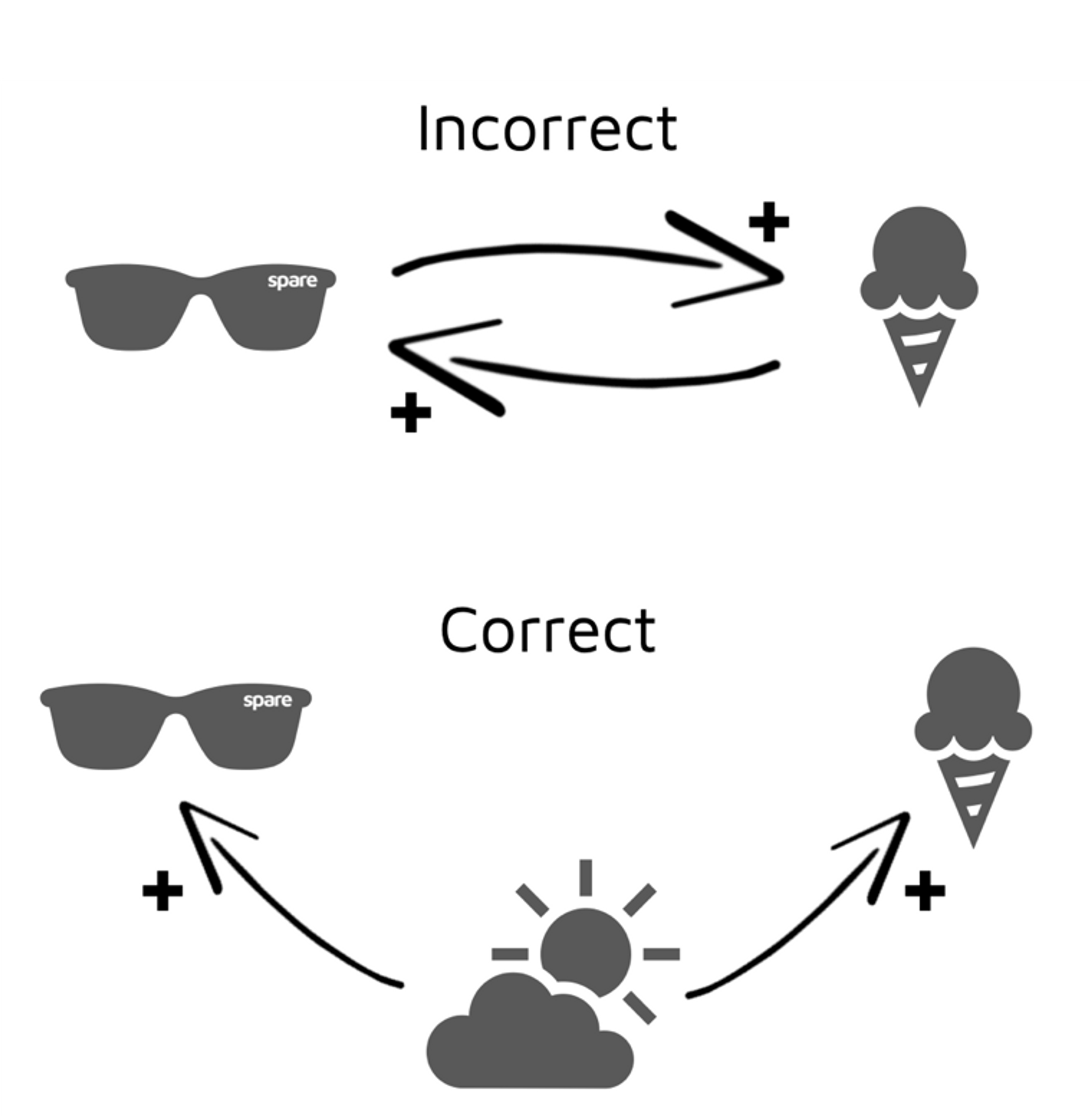
The sale of a pair of sunglasses does not cause the sale of an ice-cream. A lurking variable, sunshine, controls the relationship between the two.
The ice-cream/sunglasses case is a classic example of a commonly heard phrase:
‘Correlation does not imply causation!’
If we take this statement to be true – and it is, by the way – what hope can we ever have to confidently say to our colleagues, ‘x causes y’?
Observing the unobservable: A brief intro to causal inference
Here is where we turn to a different mathematical toolbox, known as causal inference. Causal inference goes one step further than correlation by showing us how changing one variable – in data science speak, an ‘intervention’ – will cause a change in another variable. In this way, we can directly relate cause to effect.
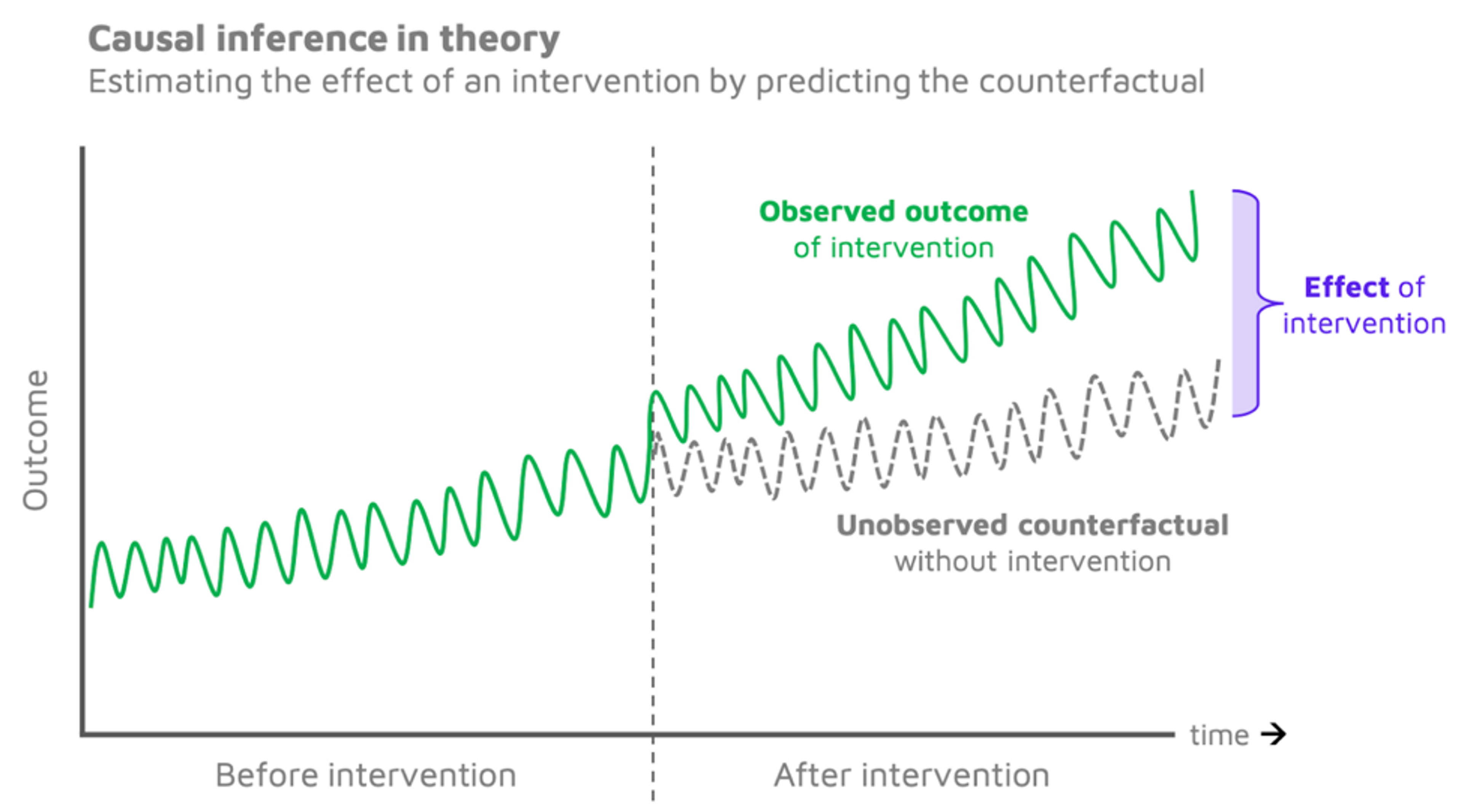
At the core of causal inference lies the concept of the counterfactual: a scenario that did not happen, but feasibly could have happened in the absence of an intervention. For instance, if our intervention was to add a fleet of new buses to a city’s transportation system to test its impact on waiting times, the counterfactual would be what happened to waiting times without the new fleet.
Since it is literally impossible to observe a counterfactual, we cannot truly know what it would have been. However, advanced statistics allow us to have a good go at predicting the counterfactual. By comparing that counterfactual to the patterns observed in real life, we can quantify the theoretical effect of our intervention. You could say we were predicting the future that never happened 😲.
Pulling the levers on a transit system
Now let’s walk through a causal inference project we recently undertook for one of our transit agencies. In the interests of confidentiality, we have removed all identifiable information about the transit service in question, but it is the real data we worked with!
Our task was simple: find out the most efficient way to run the service. In practice, this means minimising the distance that each transit vehicle travels without any riders on board, and pooling riders as much as possible (i.e. making them share their journeys with other riders).
Luckily, the Spare Engine is equipped with a neat lever that can be pulled to change the system’s optimisation: it allows us to either prioritise the needs of individual riders (say, through shorter waiting times), or the overall efficiency of the system.
To test the impact of our lever, we came up with two experiments: one where the lever was set to make the system work more efficiently overall, and another where it was optimized for the individual rider. Each experiment was run in succession for a period of two weeks. In the spirit of confidentiality, we cannot divulge their order.
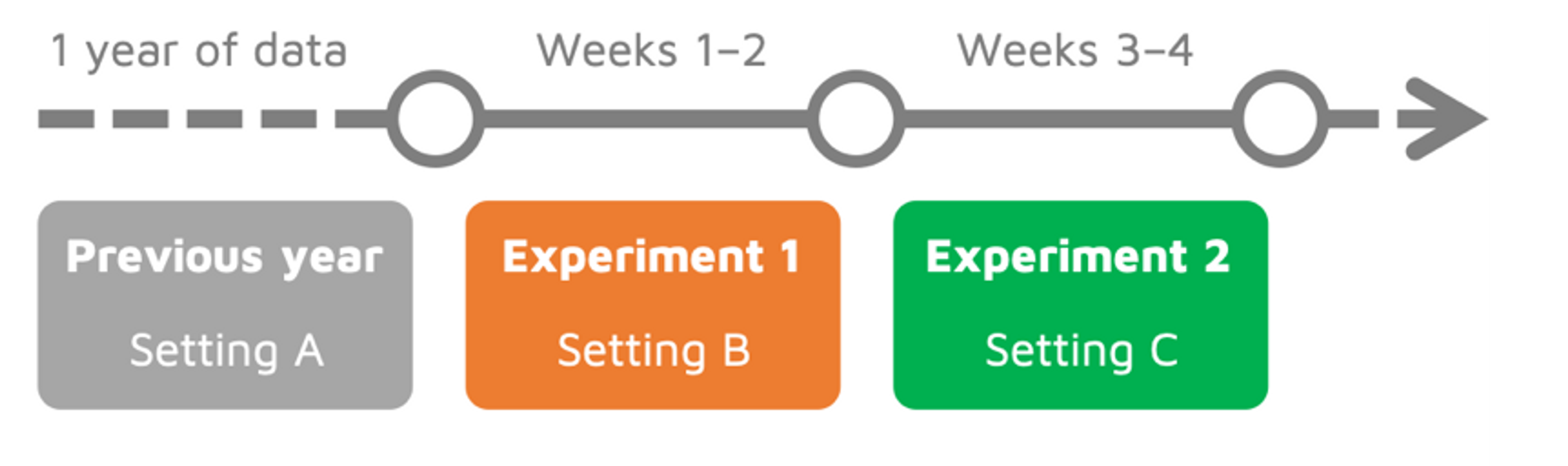
We changed the efficiency setting over the course of two experiments that lasted two weeks each. We compared the outcome of each experiment to the counterfactual, which was calculated using the previous year’s data.
Since we had no way of running the experiments simultaneously on different user samples, this did not count as a classic A/B test. Instead, we had to model the counterfactual that would have occurred in the absence of the two experiments, and compare its outcome to what actually happened in real life.
For this we used the powerful open-source modelling tool Prophet. It uses some nifty statistics to break down our data into its yearly, monthly, weekly and hourly trends, which it then recombines to come up with a reliable counterfactual scenario.
Do we have any Spare change?
So, did our experiments have any effect on the performance of our service? Looking first at the total number of boardings during our experimental month, we found that Experiment 1 resulted in a 10% boost in daily ridership compared to the counterfactual. Experiment 2, meanwhile, resulted in a slightly less drastic 4% increase.
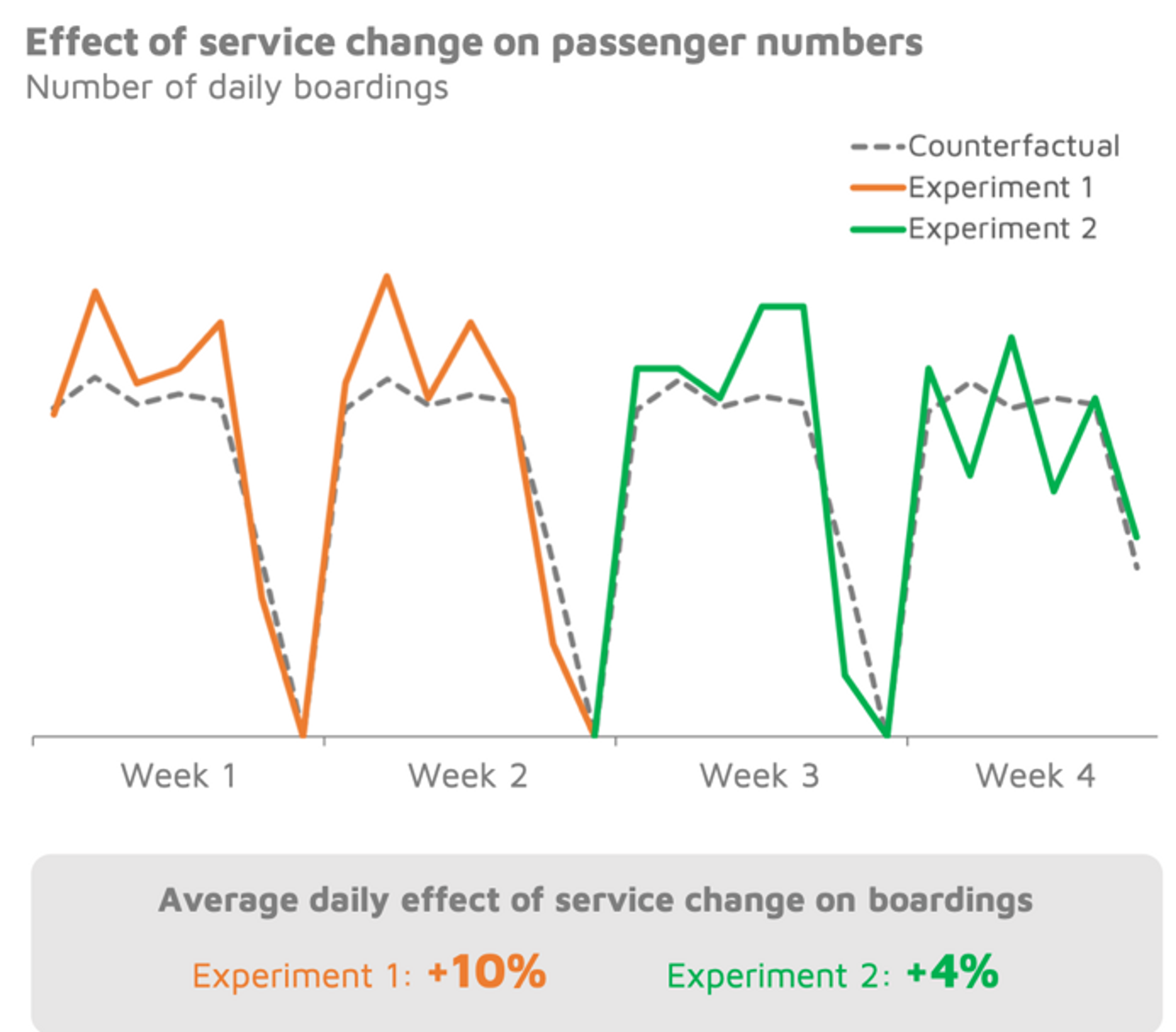
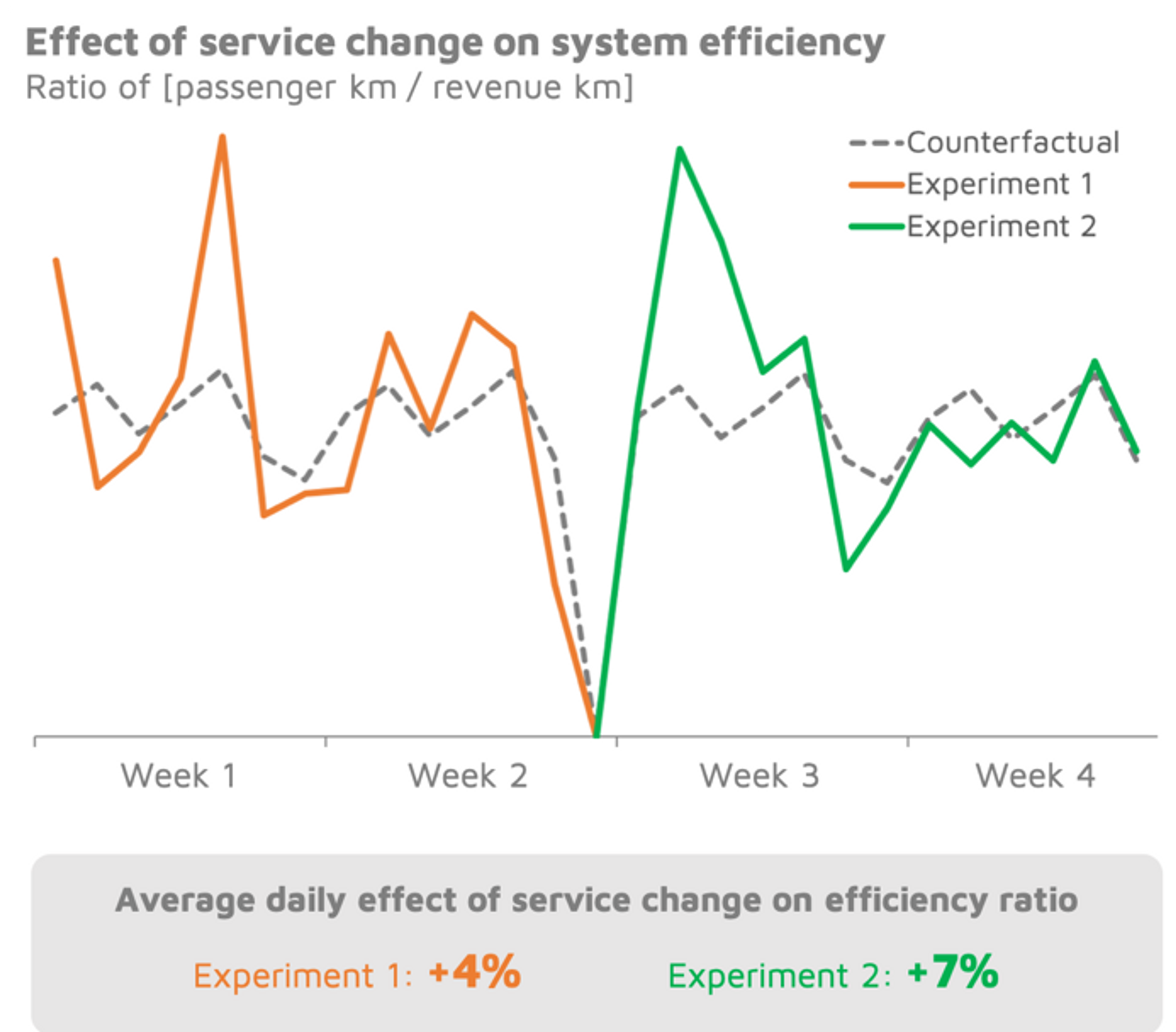
While it is important to increase the number of passengers boarding our vehicles, this should ideally not be at the expense of the system’s overall efficiency. So we conducted the same analysis on a ratio commonly used as an indicator of efficiency: the ratio of passenger kilometres to revenue kilometres. The more pooling that occurs, the greater this ratio becomes.
We found that it was actually Experiment 2 that resulted in the biggest increase in the efficiency ratio, with a 7% improvement relative to the counterfactual. Experiment 1 led to a 4% improvement, implying that its boost in boardings came at the expense of driving many more kilometres with an empty vehicle – not ideal!
With this evidence in hand, we suggested to our clients that the settings of Experiment 2 might help them improve the efficiency of their service in future. Ultimately, this will likely result in lower costs as well as a better experience for their riders.
By applying some snazzy maths to the high-resolution data spat out by the Spare Engine, we painted a future that never happened 😲 to understand the impact of changing a single variable in a transit system. An obvious way to improve this would be to run our experiments for longer, and at different times of the year, to give us more certainty about our outcomes.
We are also planning a related A/B experiment where we simultaneously expose two similar services (in terms of size, demographics and rider behaviour) to two different slider settings. We will then apply a more varied set of statistical tests to further eke out the link between cause and effect.
One final thing: most transit systems serve a purpose higher than simply generating revenue. Managed well, they can be crucial for enhancing community cohesion, improving the environment and spreading wealth and opportunity more equitably. Any changes made to transit should therefore be based on a holistic understanding of the system, not just a single metric or group.
In our efforts to reimagine mobility, we at Spare are keenly aware of our responsibility for keeping an eye on all the forces at play.
To find out more about how Spare powers on-demand transportation of any type or size, don’t hesitate to get in touch with us at hello@sparelabs.com.